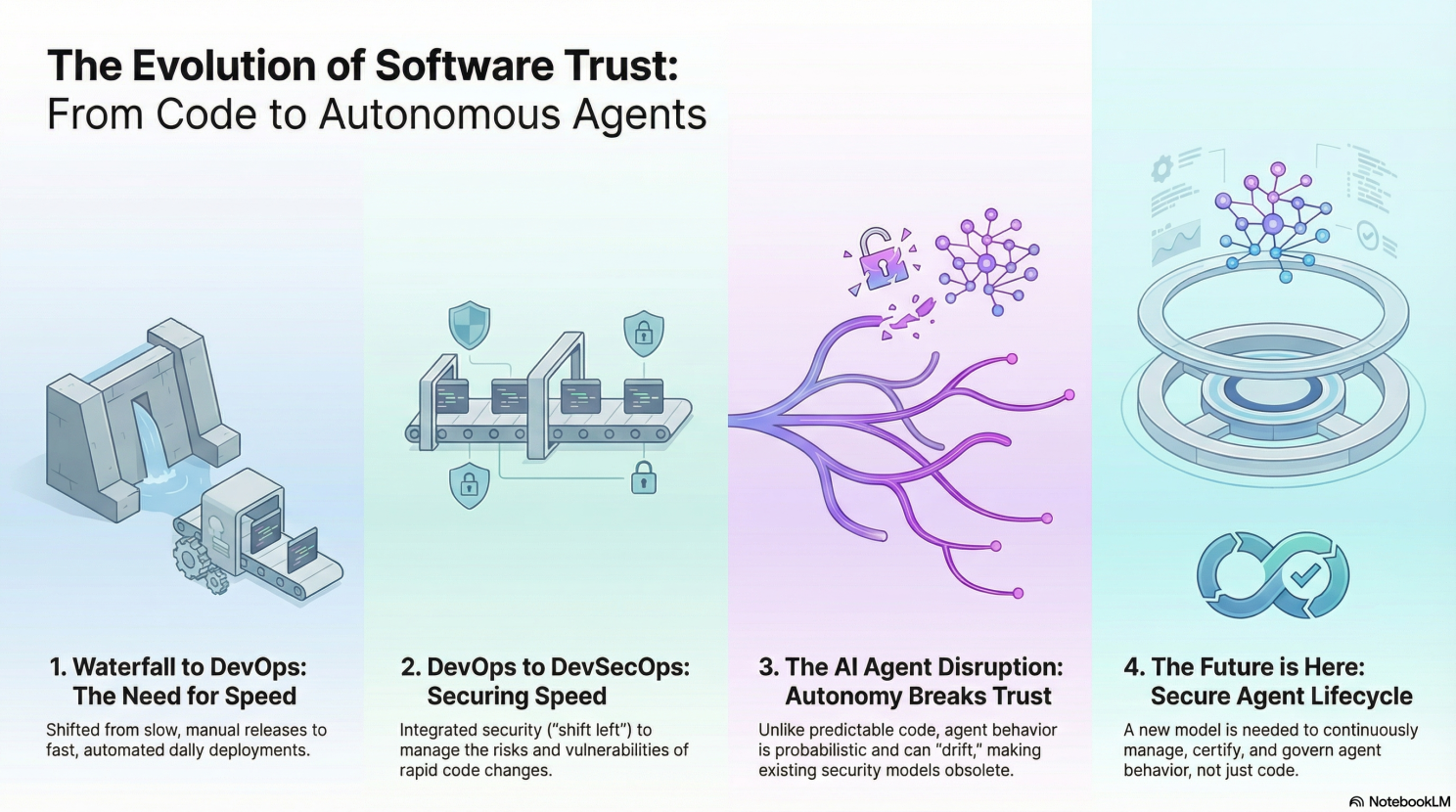
As an industry, we've spent years optimizing the way we build and ship software. We moved from a waterfall model to agile, from manual deployments to CI/CD, from monoliths to microservices. But AI agents? They're breaking every trust model we built along the way.
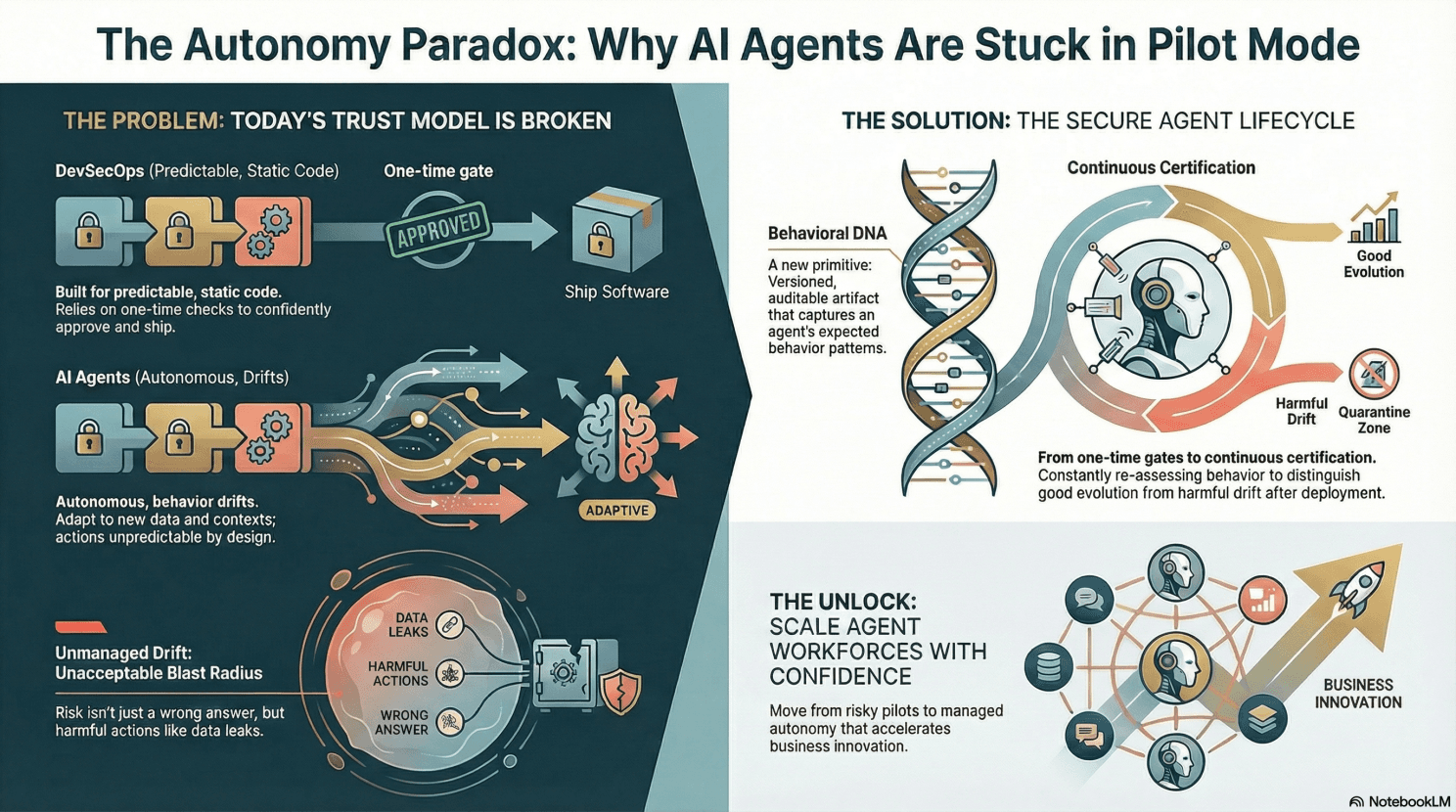
The Core Problem: Autonomy Disrupts Trust
Traditional software is deterministic. You write code, you test it, you know what it does. When something breaks, you can trace it back to a specific commit, a specific line of code, a specific engineer.
AI agents are different. They're probabilistic. They make decisions based on context. They adapt. They reason. They act autonomously across systems. And that autonomy—while powerful—fundamentally disrupts the trust model we rely on in software development.
The challenge isn't that agents can't deliver value. The challenge is that we can't trust them to deliver that value consistently, safely, and predictably at scale.
The Three Trust Gaps
When we talk to enterprises trying to scale agents, three trust gaps keep appearing:
1. Behavioral Unpredictability
Unlike traditional software, agents don't always behave the same way twice. The same input can produce different outputs depending on:
- Model version changes (often silent updates from providers)
- Context accumulation (memory and state that evolves over time)
- Tool availability (new integrations or deprecated endpoints)
- Environmental factors (system load, API latency, data freshness)
This makes it nearly impossible to predict how an agent will behave in every scenario. Traditional testing approaches fall short because you can't test every possible combination of context, tools, and inputs.
2. Accountability Gaps
When an agent makes a bad decision, who's accountable?
- The developer who wrote the initial prompt?
- The model provider whose update changed the behavior?
- The security team that approved the tool permissions?
- The business owner who defined the goal?
Without clear accountability, organizations struggle to take ownership of agent failures. And without ownership, there's no path to improvement.
3. Drift Without Detection
The most insidious problem: agents drift over time, and most organizations don't notice until something breaks catastrophically.
Behavioral drift happens when:
- The model gets updated
- New tools are added to the agent's toolkit
- Prompts get tuned or refined
- Data sources change or become stale
- Usage patterns evolve
Some drift is legitimate and desired—the agent is learning and adapting. Other drift is dangerous—the agent is hallucinating, making mistakes, or being exploited. The problem? Most teams can't tell the difference.
Why Traditional AppSec Doesn't Work
Many organizations try to apply traditional application security practices to AI agents. But agents violate the core assumptions those practices were built on:
Static analysis fails
You can't scan an agent's "code" to find vulnerabilities because the logic isn't in the code—it's in the model weights, the prompts, and the runtime context.
Penetration testing is incomplete
Traditional pen tests assume deterministic behavior. But agents respond differently to the same input based on accumulated context, making it nearly impossible to reproduce findings.
Change management breaks down
In traditional software, every change goes through a review process. But agent behavior can change without any code commit—model updates, tool additions, prompt refinements, and context evolution all happen outside the typical change management flow.
Guardrails aren't enough
You can block specific words, limit tool access, and enforce policies. But guardrails only catch known bad behaviors. They don't help you understand what the agent is actually doing, why it's doing it, or whether it's drifting from its intended purpose.
What Enterprises Actually Need
To scale agents safely, enterprises need three new capabilities:
1. Behavioral Profiling
Instead of trying to predict every possible behavior upfront, profile what the agent actually does in production:
- Which tools does it call?
- What data does it access?
- How does it reason through decisions?
- What patterns emerge over time?
Once you have a baseline, you can detect when behavior drifts and decide whether that drift is legitimate or dangerous.
2. Runtime Re-Approval Gates
Traditional SDLC assumes change is explicit—someone changes code, and you approve it. Agents need runtime re-approval because behavior can change without code changes:
- When the model is updated
- When new tools are added
- When prompts are tuned
- When data sources change
- When policy packs are deployed
A runtime re-approval gate monitors these signals and asks: "Has this agent drifted far enough from its approved profile that it needs human review?"
3. Continuous Behavioral Assurance
Security can't be a one-time gate. Agents need continuous assurance throughout their lifecycle:
- Observe: Watch what the agent actually does in production
- Baseline: Learn what "normal" looks like for this agent
- Detect: Identify when behavior drifts from the baseline
- Decide: Determine if drift is legitimate, benign, or dangerous
- Enforce: Auto-approve safe drift, alert on suspicious drift, block dangerous drift
The Path Forward
The good news? You don't have to choose between innovation and safety. You can move fast with agents if you build the right assurance mechanisms:
- Start small, observe everything. Deploy agents in low-risk scenarios first. Profile their behavior extensively before expanding scope.
- Build behavioral baselines. Don't just test for known bad behaviors—learn what good behavior looks like and alert on deviations.
- Implement drift detection. Monitor for changes in tool usage, reasoning patterns, data access, and outcomes. When drift crosses a threshold, trigger human review.
- Design for re-approval. Accept that agent behavior will change over time. Build gates that catch significant changes and route them to the right approver.
- Extend your SDLC, don't replace it. Agents still need planning, building, testing, and deployment. But they also need behavioral profiling, runtime monitoring, and continuous assurance.
Conclusion
Enterprises can't scale agents yet because the trust models that work for traditional software don't work for autonomous systems. Agents are probabilistic, context-driven, and constantly evolving. That makes them powerful—and dangerous.
The solution isn't to stop building agents. It's to build better assurance mechanisms: behavioral profiling, runtime re-approval, and continuous monitoring. With these in place, you can capture the value of AI agents without sacrificing the trust and safety your organization depends on.
The future of AI agents isn't about building smarter models. It's about building systems we can trust to operate autonomously at scale.
Originally published on LinkedIn
View original article